
A grammar gap-fill exercise looks deceptively simple.
A short text. A few blanks. Four options per blank. One explanation after submission.
That sounds like easy content to generate.
It is not.
For exam-oriented German learners, especially around B1, B2 and C1, this format sits close to the real failure mode. The learner is not being asked whether they have seen the rule before. They are being asked to apply it in context, while separating the correct form from nearby alternatives.
That is exactly why the format is useful. It is also why quality is hard.
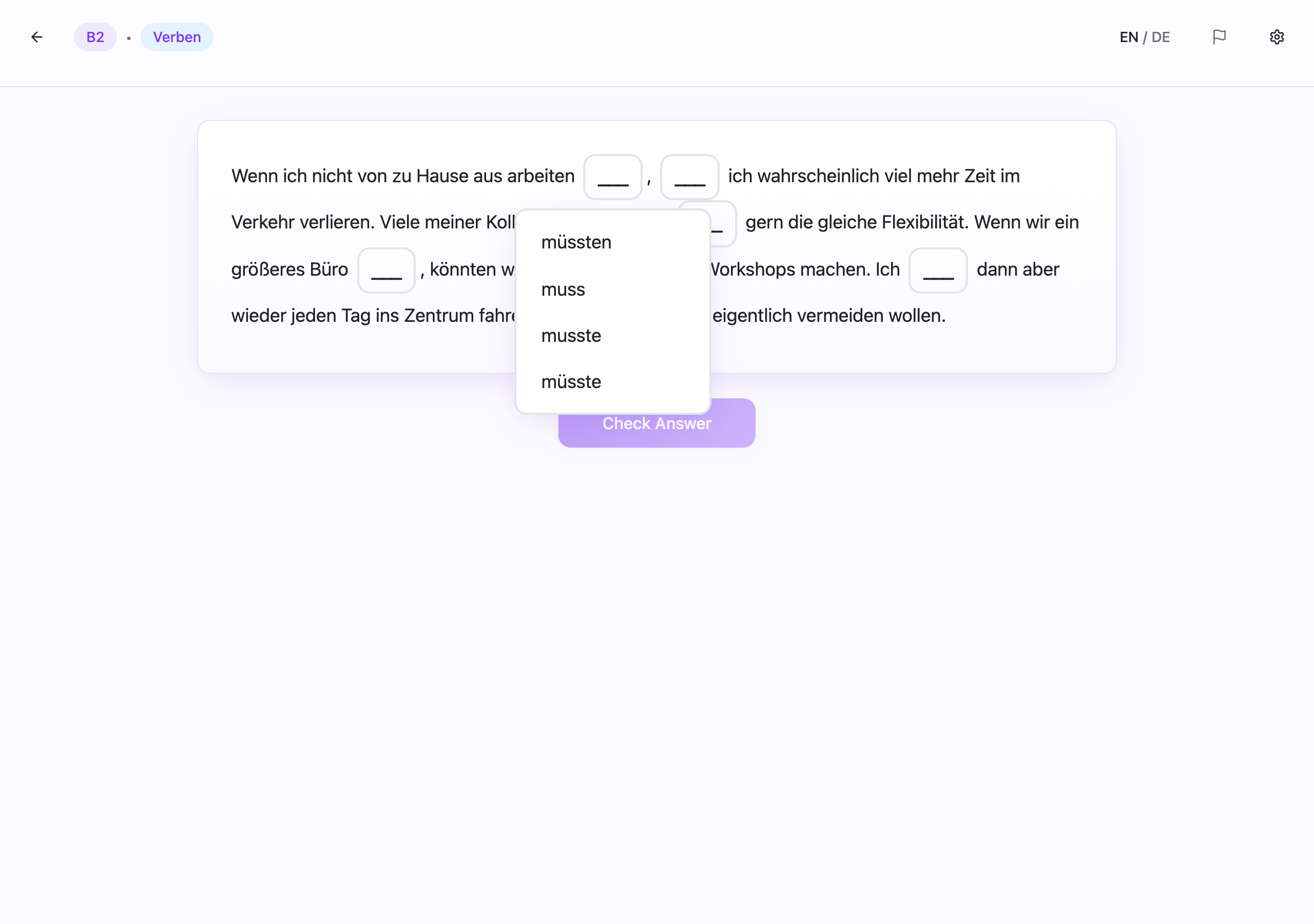
The format is simple. The specification is not.
A single exercise in InfiniteGrammar.de is a short text with multiple gaps. Each gap has:
- one correct answer,
- three distractors,
- and one explanation in German.
That only sounds routine until the quality bar is made explicit.
For one exercise to be publishable, it has to do all of the following at once:
- test the intended grammar section rather than a neighbouring rule,
- stay inside the intended CEFR band in both grammar and vocabulary,
- contain one answer that is clearly correct in context,
- contain distractors that are plausible enough to be worth choosing,
- and explain the underlying rule rather than merely validating the local answer.
That combination is tight.
A draft can look fine and still fail in important ways. A distractor may be acceptable in spoken German. The sentence may drift into vocabulary difficulty rather than grammar difficulty. The explanation may restate the answer instead of teaching the rule. The sentence may be grammatical but still sound unnatural enough that a native speaker would reject it.
So the problem is not just generation.
It is specification under ambiguity.
The real product surface is the distractor set
The correct answer is usually the easy part.
If the grammar target is narrow enough, the surrounding sentence often constrains the correct form quite strongly.
What separates a useful exercise from a weak one is usually the quality of the wrong answers.
A distractor has to do three things at the same time:
- be plausible in German,
- be wrong in this exact sentence,
- and represent a mistake that a learner at this level might realistically make.
That is much more demanding than "three wrong options."
If the target is a verb with a fixed preposition, weak distractors are obviously unrelated. Strong distractors are prepositions that are common elsewhere and therefore genuinely tempting. If the target is adjective declension, the distractors should reflect nearby case, gender, or number confusions, not random morphology.
This is why I ended up treating the exercise format less as "text generation" and more as "error modelling."
The distractors define a large part of the learning value.
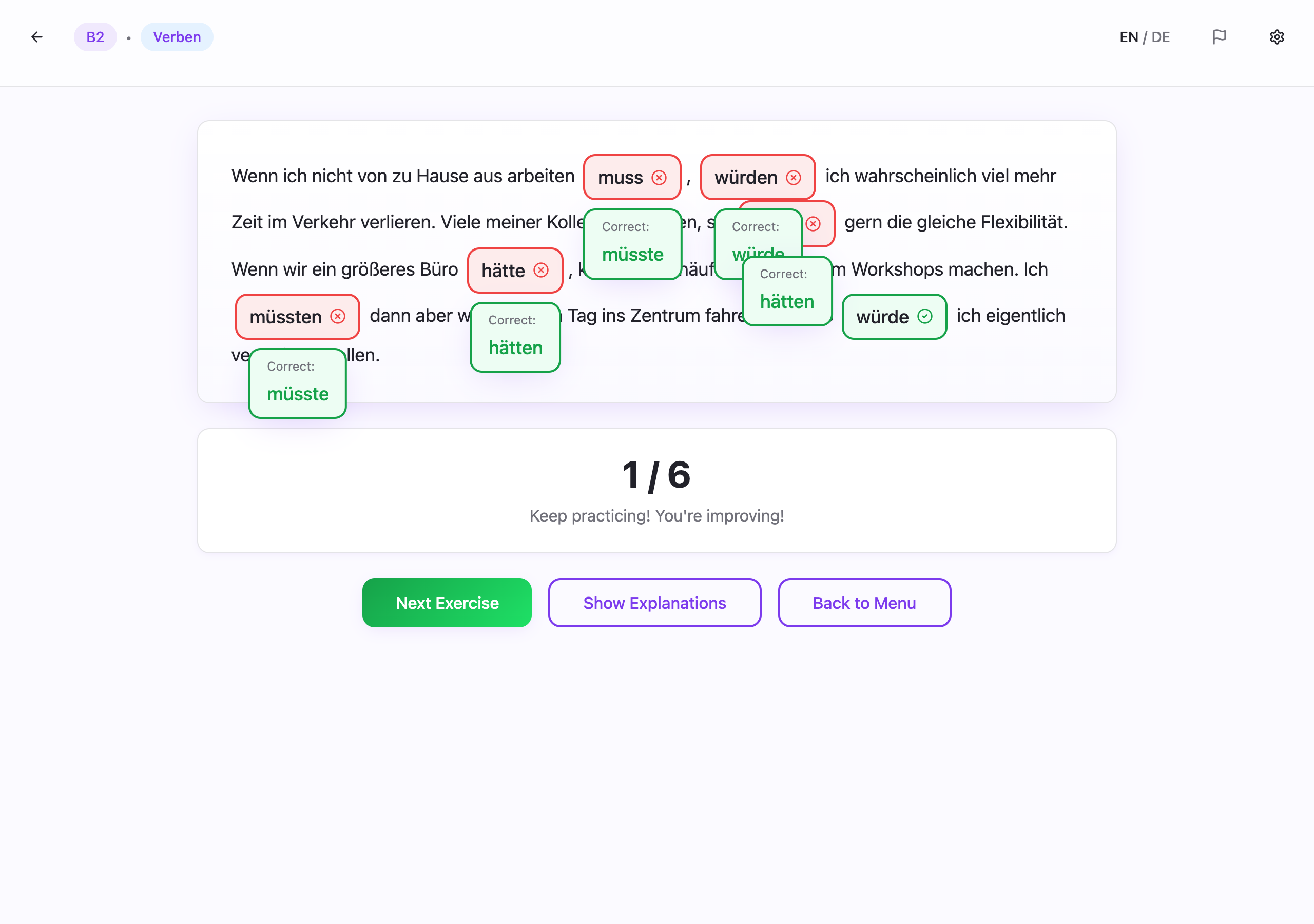
Generation had to start from a much narrower contract
A broad request such as "generate a B2 German grammar exercise" is not useful.
It leaves too many degrees of freedom open:
- which sub-pattern inside the grammar section is being tested,
- how difficult the distractors should be,
- which register the text should use,
- whether the scenario fits exam-oriented language use,
- and whether the explanation teaches anything transferable.
The generation setup became much more constrained.
Each request needs to specify:
- the grammar section,
- the CEFR level,
- the exercise format,
- the number of gaps,
- the answer structure,
- the explanation requirement,
- and the scenario or content topic.
The scenario matters more than it may seem. It is one of the easiest ways to control vocabulary distribution, stylistic register, and the practical feel of the exercise. At B2 and C1 especially, the text should not sound like filler. It should feel close to the kinds of contexts learners actually meet in exam preparation and formal language use: administration, workplace communication, housing, education, applications, and structured written tasks.
Why one-shot generation was not enough
Even with a tighter prompt, one-shot generation produced too many flawed exercises.
The recurring issues were usually not dramatic. They were small defects with product consequences:
- inconsistent gap numbering,
- malformed JSON,
- explanations in the wrong language,
- weak distractors,
- answers that were technically correct but tested the wrong rule,
- and edge cases where more than one option could be defended.
That made a review step necessary.
The generation pipeline became a generate–assess–regenerate loop with shared history:
messages = [system_prompt, generation_request]
exercise = call_llm(gen_model, messages, temperature=0.9)
messages.append({"role": "assistant", "content": exercise})
for iteration in range(max_iterations):
messages.append({"role": "user", "content": assessment_prompt})
assessment = call_llm(assess_model, messages, temperature=0.3)
messages.append({"role": "assistant", "content": assessment})
if '"status": "pass"' in assessment:
return exercise, passed=True
messages.append({"role": "user", "content": regeneration_prompt})
exercise = call_llm(regen_model, messages, temperature=0.9)
messages.append({"role": "assistant", "content": exercise})The important design choice is the shared messages array.
Without that shared context, regeneration is basically just another attempt. With it, the model sees the draft, the critique, and the reasons the exercise failed. That at least makes targeted repair possible.
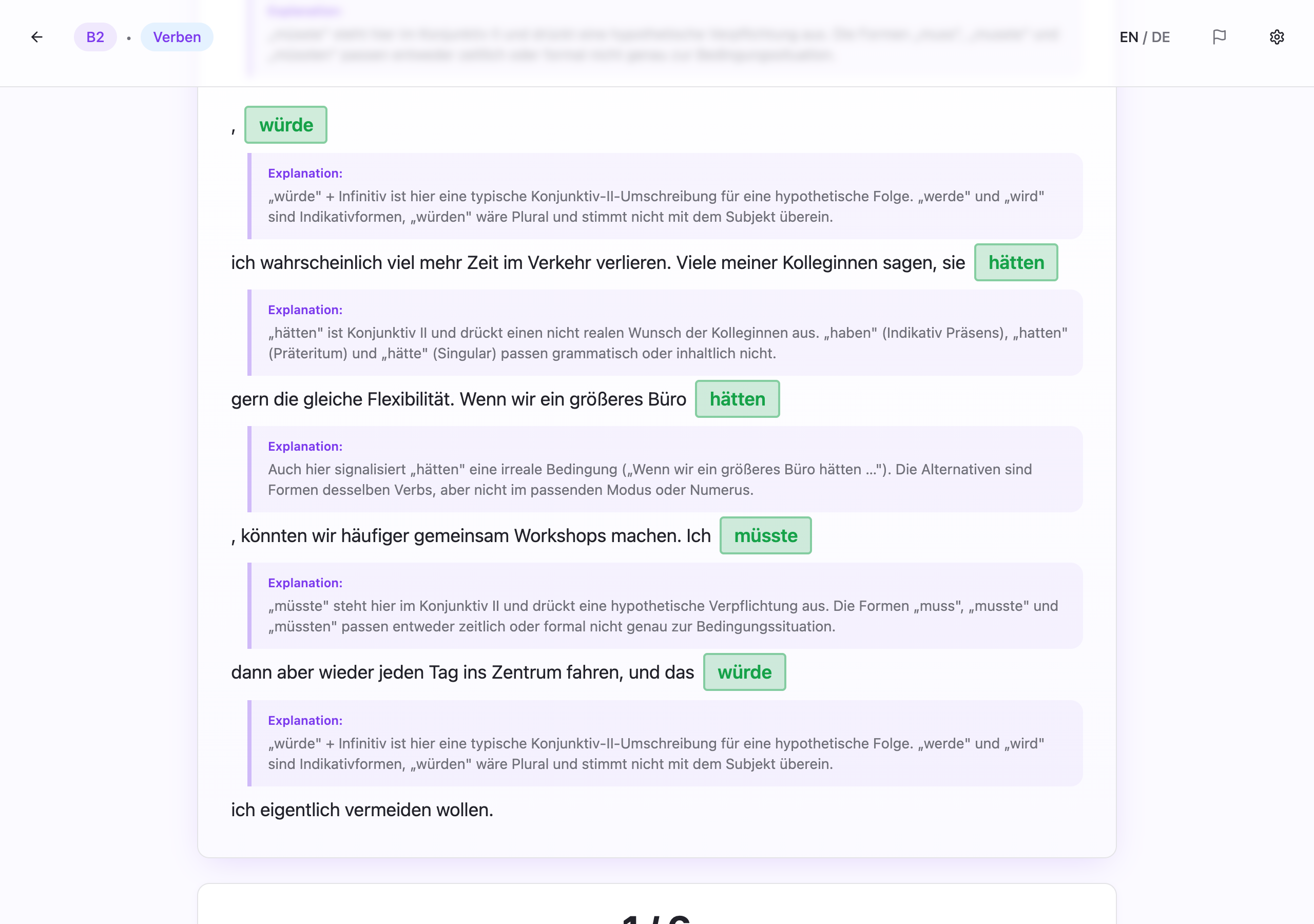
What the loop is good at
The loop improves a lot of things reliably.
It is good at structural defects:
- missing fields,
- broken formatting,
- inconsistent numbering,
- output-contract violations,
- obvious mismatches between the grammar section and the actual gaps.
It is also reasonably good at catching extreme level mismatches. If an A2 exercise suddenly contains unexpectedly advanced syntax, or a B2 exercise collapses into something too elementary, the assessment step often catches that.
That matters, because these are exactly the defects that make generated content unusable at scale.
What the loop is not good enough at
The harder failures are linguistic rather than structural.
This is where the uncomfortable limitation appears.
The model can still approve subtly wrong German: constructions that are almost right, distractors that are too plausible, explanations that validate a shaky answer, or sentence frames that are technically grammatical but not idiomatic enough.
The loop raises the floor. It does not guarantee correctness.
That is the important distinction.
For a learning product, "substantially better than raw generation" is useful. It is not the same as "reliably correct." And that difference matters because a learner who internalizes a wrong pattern is worse off than a learner who got no exercise at all.
The loop is still worth having
That limitation does not make the loop pointless.
Quite the opposite.
The loop is valuable because it turns implicit quality requirements into an explicit review contract. It forces the system to say, in operational terms, what a good exercise is supposed to be.
That already changes the quality of the output.
It also changes the way content generation is discussed. Once the rubric exists, the problem stops being "can the model generate German exercises?" and becomes "which classes of mistakes are structural, which are linguistic, and which still need another control layer?"
That is a much more useful question.
The practical conclusion
The format looks simple because the interface is simple.
The content problem is not.
A good gap-fill exercise is not just a short text with blanks. It is a compact system of constraints around grammar targeting, CEFR control, distractor quality, and explanation quality.
That is why exercise generation in InfiniteGrammar.de never became "just ask an LLM for content."