
After a grammar section contains enough material, a new question appears.
Are these genuinely different exercises, or just many versions of the same one?
That sounds straightforward until you try to measure it.
Off-the-shelf sentence embeddings were not especially useful here. Two exercises can be semantically close because they both describe travel while testing different grammar. They can also be semantically distant while still feeling repetitive to a learner because the sentence structure, gap pattern, and answer morphology are nearly identical.
What mattered operationally was not "topic similarity" in the generic NLP sense.
It was something more specific:
How likely is a learner to experience these two exercises as redundant?
A single embedding answered the wrong question
The failure mode of plain sentence embeddings was easy to spot.
- Same topic, different grammar → similarity too high
- Different topic, same grammatical scaffold → similarity too low
That is a poor fit for a product where repetition is often structural rather than semantic.
An exercise about travel and an exercise about housing may feel very different topically while still drilling the same pattern in almost the same way. From a learning point of view, that is not enough variation.
So the similarity model had to be decomposed.
Similarity had to be treated as a multi-part signal
The representation used in the pipeline combines four feature blocks.
1. Word-level TF-IDF on the filled-in text
This captures lexical overlap and topic repetition.
If two exercises repeatedly use the same vocabulary field, this block will show it.
2. Character n-grams on the correct answers
This captures morphological overlap.
Two exercises can differ in surrounding nouns and verbs while still testing nearly identical inflection patterns. Character n-grams help expose that.
3. Structural features
This block includes things such as:
- gap count,
- average answer length,
- text length,
- average gap position,
- distractor count,
- and vocabulary-richness proxies.
This is not glamorous, but it matters. Exercises can become repetitive simply because they are shaped the same way.
4. POS n-grams via spaCy
This is where the syntactic scaffold becomes visible.
Two exercises can use different words and still repeat the same clause pattern, agreement mechanics, and target-slot position. POS n-grams are a practical way to capture that without building a full symbolic grammar engine.
In simplified form, the weighting looks like this:
FEATURE_WEIGHTS = {
"text_tfidf": 0.35,
"answers_char_ngrams": 0.25,
"structure": 0.15,
"pos_ngrams": 0.25,
}Each block is normalized independently, weighted, concatenated, and then compared using cosine similarity.
The important point is not the exact coefficients.
The important point is that the model of similarity is explicitly multi-view. It encodes what "too similar" means for this product.
Why spaCy mattered here
spaCy was useful because perceived repetition is often structural.
Two exercises can use different nouns and verbs while still repeating the same scaffold. For example, two sentences may both drill the same dative pattern in the same syntactic slot. A learner will often experience those as highly related even if a semantic model does not.
That is where POS n-grams help.
They do not solve the whole problem. They simply add a missing dimension that plain semantic similarity tends to miss.
Pairwise cosine scores are necessary and not sufficient
Raw pairwise similarity is useful, but not yet operational.
A section with 40 exercises already has 780 pairs. A list of scores is not editorial support.
That is why the pipeline stores both pairwise similarities and higher-level aggregates:
- section-level mean and max similarity,
- distribution buckets,
- per-exercise max similarity,
- and clustering structures for visualization.
The bucket view became especially useful in the admin area:
0–0.100.10–0.250.25–0.500.50–0.75>0.75
The last bucket is the action bucket.
Anything above roughly 0.5 deserves direct review as a near-duplicate candidate.
Clustering made the output legible
Clustering was the step that made the similarity system easier to trust.
The pipeline stores a SciPy-compatible linkage matrix per section, and the frontend reconstructs it as a dendrogram. That makes families of related exercises visible quickly.
This matters because pairwise similarity is flat. It tells you that A and B are close. It does not tell you whether A and B are part of a larger cluster of five exercises that all merge at high similarity.
The dendrogram and the heatmap answer different questions:
- the heatmap shows where local overlap is dense,
- the dendrogram shows whether the overlap forms a family,
- the pair detail view answers whether the family is genuinely redundant or merely related.
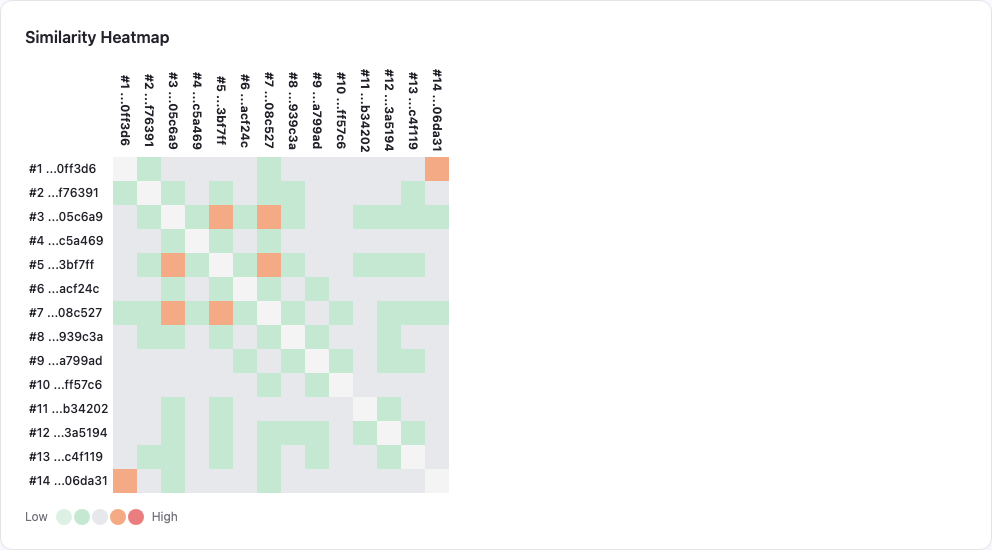
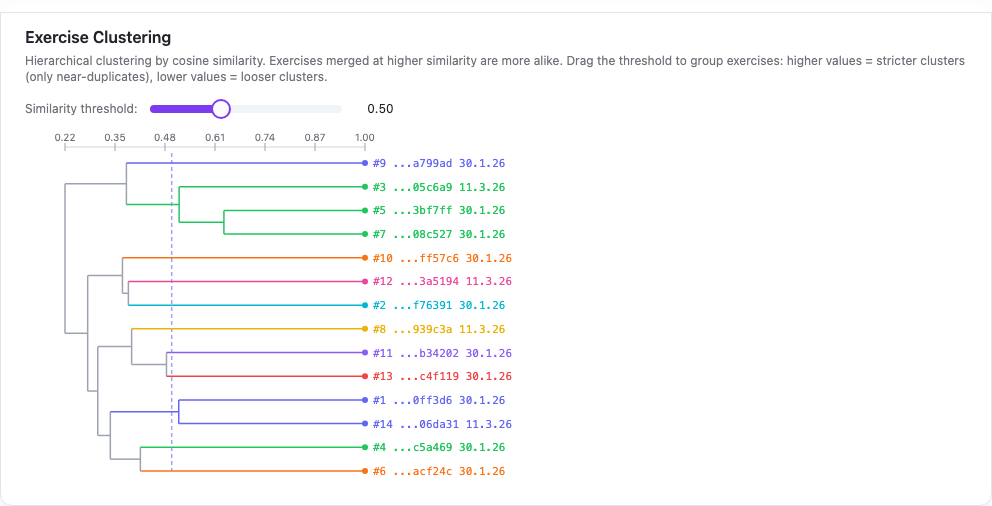
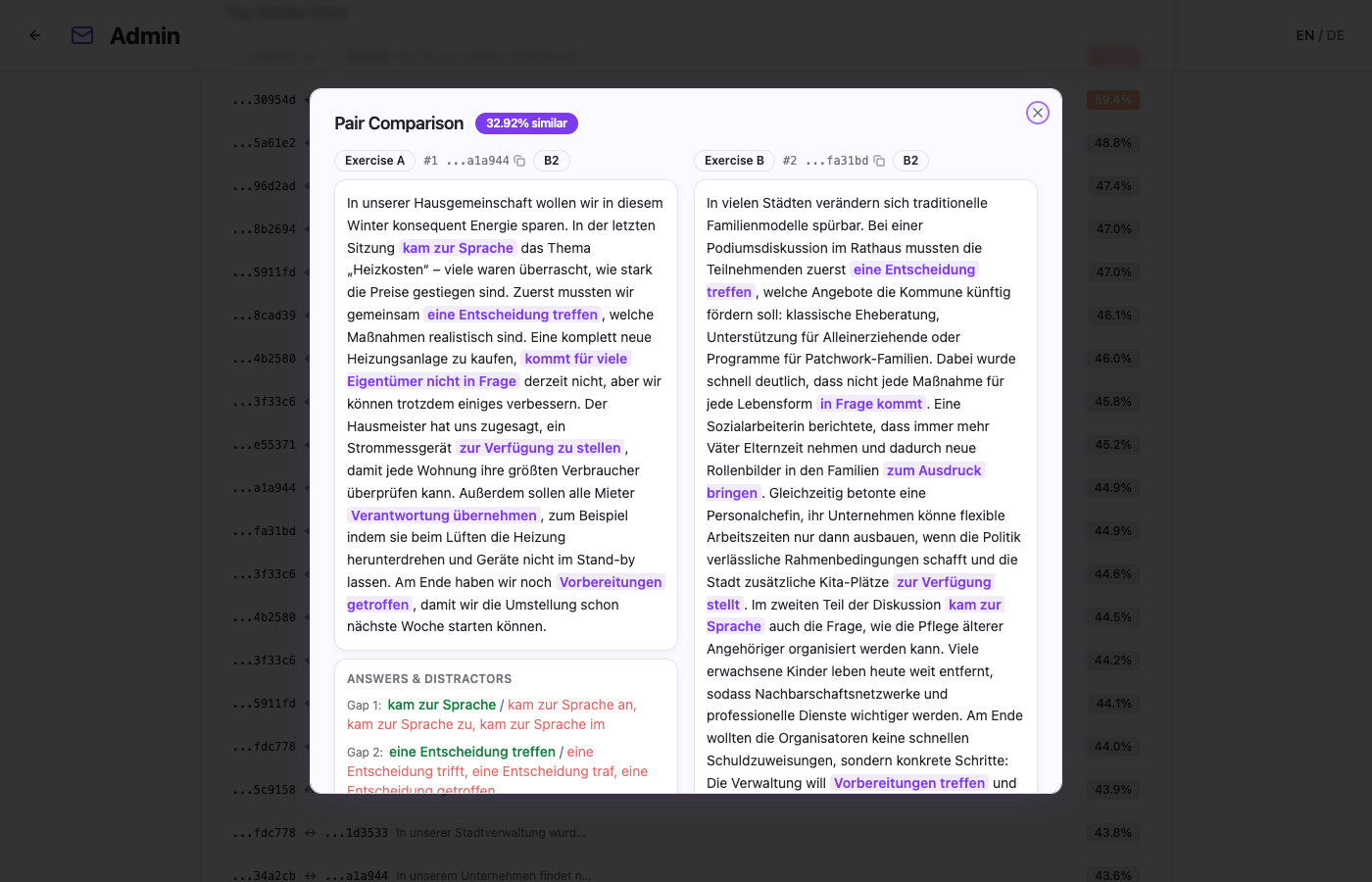
This progressive drill-down turned the metric from an abstract score into an editorial tool.
Sequential neighbor similarity
The pairwise heatmap answers which exercises are similar. It does not answer whether similar exercises are placed next to each other in the sequence a learner actually sees.
That is what the sequential neighbor strip shows. For each exercise, it displays the cosine similarity to the next 1–5 exercises in order. Orange or red in the +1 column means the learner will encounter two exercises back-to-back that feel repetitive.
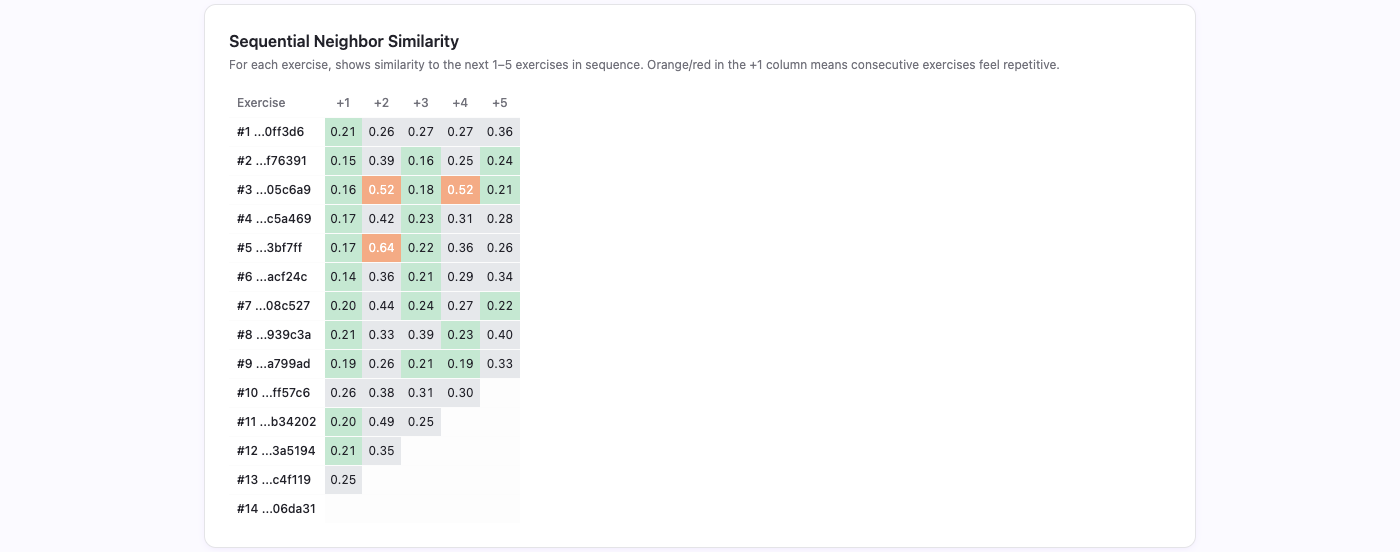
This view feeds directly into the reordering pipeline. If two exercises with high pairwise similarity happen to be sequential neighbors, the ordering algorithm tries to separate them.
The metric changed content planning
The most practical effect of the similarity pipeline was that generation stopped being driven only by volume.
Before the metric, the instinct was easy: add more exercises where the library looks thin.
After the metric, the question became better:
- which sections are underfilled,
- which sections are over-clustered,
- which sections have enough items but not enough variation,
- and where does the next batch need to change the internal shape of the set rather than simply increase count?
That is a much better operating question.
What the system still does not know
The metric measures overlap.
It does not measure pedagogy directly. The pipeline does something important, but limited. It does not answer questions "is this a good learning sequence?" or "what is the completeness of the grammar section's exercises?"
It answers a more modest and still useful question:
Where is the corpus likely to be repeating itself in ways that deserve editorial attention?
That turned out to be an important step to making the content quality measurable and sequencing deliberate.