
Once I had pairwise similarity scores for every exercise in a grammar section, a new problem became visible: even a reasonably diverse section can feel repetitive if similar exercises appear back to back.
A learner does not experience the corpus as a similarity matrix. A learner experiences it as a sequence. That shifted the question from "are these exercises too similar overall?" to:
In what order should they appear so that practice feels varied without breaking learner progress?
That turned out to be partly an optimisation task and partly a product-constraint problem.
Why order matters even when the content is acceptable
A grammar section can contain thirty or forty individually acceptable exercises and still create a poor learning experience. If several consecutive exercises use the same content frame, the same sentence scaffold, or the same narrow variant of a grammar rule, the learner feels stuck repeating the same task — even if, measured globally, the section looks diverse.
Similarity analysis told me which pairs looked close. It did not tell me whether the learner would encounter those pairs consecutively. A content system that ignores order leaves part of the learning experience to chance.
The optimisation objective
The goal is to find an ordering that minimizes similarity between consecutive exercises:
minimize = sum(similarity(ex_i, ex_i_plus_1) for i in range(n - 1))This is closely related to a travelling-salesman-style path problem. The search space grows too quickly for exact optimisation, so the real question is how to find a sequence that is clearly better than insertion order or random shuffle. I used a two-step heuristic.
Step 1: greedy nearest-neighbour seeding
Start from the most "central" exercise — the one with the highest average similarity to all others — and repeatedly append the least similar remaining exercise:
start = int(np.argmax(sim_matrix.mean(axis=1)))
visited = [False] * n
sequence = [start]
visited[start] = True
for _ in range(n - 1):
current = sequence[-1]
best_next = min(
(j for j in range(n) if not visited[j]),
key=lambda j: sim_matrix[current][j]
)
sequence.append(best_next)
visited[best_next] = TrueThis produces a strong baseline quickly. It forces the sequence away from local similarity instead of inheriting generation order. But it leaves local defects behind, especially in sections with multiple internal clusters.
Step 2: 2-opt improvement
2-opt is a standard local-search heuristic. It tries reversing every possible segment and keeps the reversal if it reduces the total similarity cost:
for i in range(n - 1):
for j in range(i + 2, n):
delta = 0.0
if i > 0:
delta -= sim_matrix[sequence[i - 1]][sequence[i]]
delta += sim_matrix[sequence[i - 1]][sequence[j]]
if j < n - 1:
delta -= sim_matrix[sequence[j]][sequence[j + 1]]
delta += sim_matrix[sequence[i]][sequence[j + 1]]
if delta < -1e-9:
sequence[i:j + 1] = sequence[i:j + 1][::-1]
improved = True2-opt reliably cleans up the most visible local mistakes left by the greedy pass. Small runs of similar exercises become more evenly distributed without requiring an expensive exact solver.
Random shuffle, by comparison, is not a neutral baseline. If a section contains topic clusters, random order still tends to leave local runs of similar items. The difference between shuffled order and similarity-aware order is visible immediately in the dashboard heatmaps.
The constraint that mattered more than the algorithm
Learners progress through a grammar section in order. That progress is stored as the last completed exercise position. Reordering an entire section after learners have started it would break their progress pointer — they could re-encounter completed material, skip unseen material, or resume into a sequence that no longer makes sense.
So the reordering system has two modes:
- complete mode — reorder the full section when no one has started it,
- untouched mode — reorder only exercises that no learner has completed yet.
touched_ids = db.fetch_touched_exercise_ids(conn, grammar_section_id)
locked = [ex for ex in all_exercises if str(ex['id']) in touched_ids]
free = [ex for ex in all_exercises if str(ex['id']) not in touched_ids]The locked prefix keeps its positions. Only the remaining exercises are reordered. A global optimum that breaks learner continuity is not a good solution — a weaker local optimum that respects learner progress is the right product decision.
There is one additional detail at the boundary: the first free exercise is selected to be as dissimilar as possible from the last locked exercise, because that is exactly where the learner resumes. This reduces the chance that the learner returns into a near-duplicate of something they just completed.
Two metrics make reordering decisions actionable
Reordering without measurement is guesswork. The admin dashboard tracks two custom metrics that make the quality of each section’s sequence visible and comparable across runs.
Weighted Neighbourhood Score (WNS)
Weighted Neighbourhood Score (WNS) measures the weighted average similarity of each exercise to the next five exercises in the sequence. The weights decrease exponentially: the immediate next exercise contributes 50%, the one after that 25%, then 12.5%, 7.5%, and 5%. This reflects how learners actually perceive repetition — the immediate neighbour matters most.
Lower is better. The dashboard uses colour-coded thresholds to make this actionable at a glance:
- green (WNS ≤ 0.20) — good sequence variety, no action needed,
- orange (WNS 0.35–0.50) — noticeable local repetition, reordering recommended,
- red (WNS > 0.50) — strong local repetition, reordering or content review needed.
A WNS above 0.35 is the threshold that triggers a reordering recommendation in the dashboard.
Ordering Quality Ratio (OQR)
Ordering Quality Ratio (OQR) is a rank-based metric that compares where adjacent-pair similarities sit within the full pairwise similarity distribution. It answers the question: are the exercises that happen to be neighbours in the sequence more or less similar than the average pair in the section?
The early version used a simple mean-ratio formula, but that turned out to be misleading — it shifted when the number of exercises changed even if the actual sequence quality did not. The current version is rank-based, which makes it scale-invariant and stable across sections of different sizes.
Lower is better. An OQR near 0 means adjacent pairs are drawn from the least similar end of the distribution — exactly what good sequencing should produce. The dashboard displays this alongside WNS, so the two metrics reinforce each other: WNS shows the absolute local similarity, and OQR shows whether the ordering is making efficient use of the available diversity.
The dashboard ties it all together
Both metrics are stored per similarity run in the section_similarity_summary table, alongside the exercise order snapshot that existed at the time of the run. That makes historical comparison meaningful: when comparing two runs, the dashboard shows each run’s metrics against its own ordering, not today’s.
The practical workflow is:
- Run similarity analysis for a section — the dashboard shows WNS, OQR, and a heatmap of the current order.
- If WNS > 0.35 or the heatmap shows visible clustering along the diagonal, trigger a reorder.
- After reordering, run similarity again — compare the new WNS and OQR against the previous run to confirm improvement.
This turns exercise sequencing from a one-time operation into a repeatable quality check. Sections that receive new exercises can be re-evaluated and reordered without guessing whether the change helped.
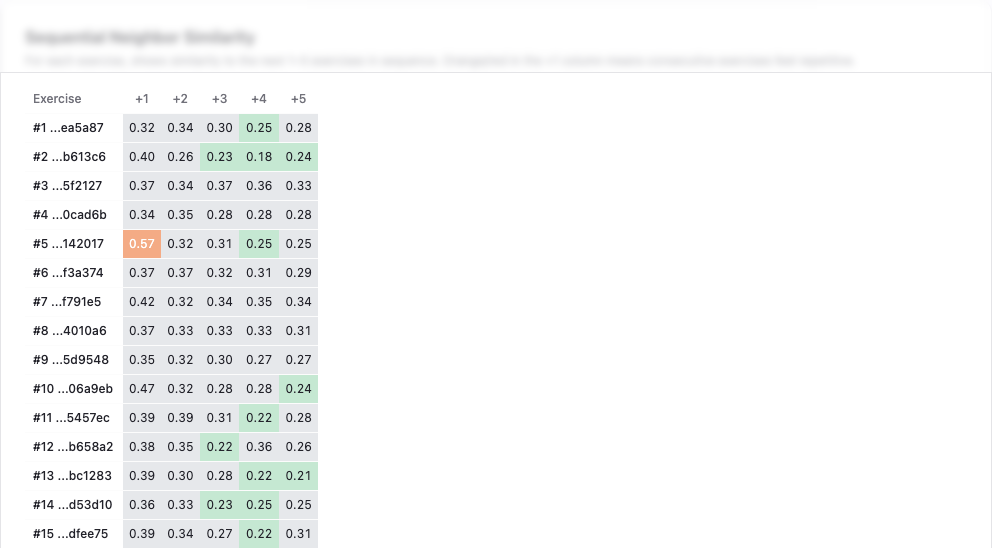
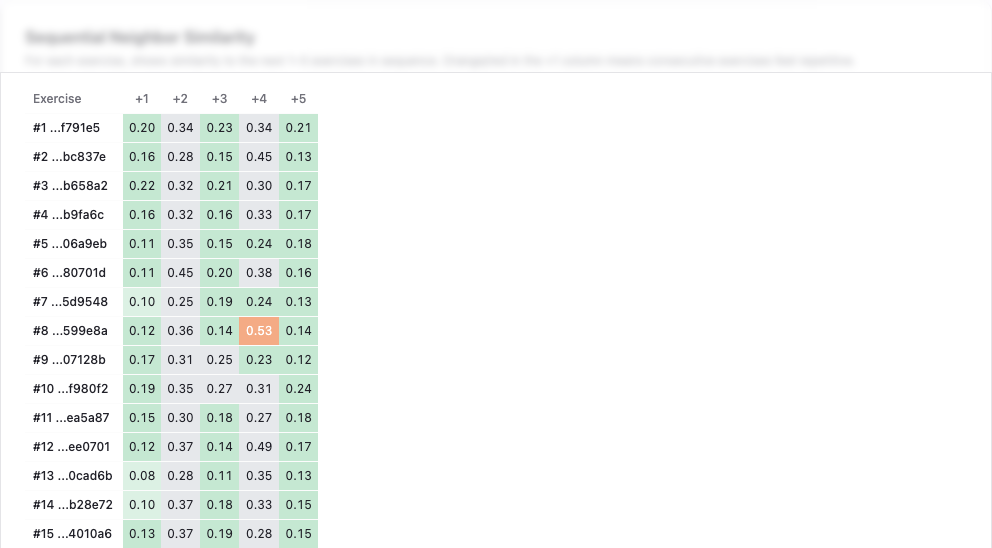
What sequencing actually changed
Reordering does not create diversity that is not there. It cannot fix a section whose underlying exercises are all too similar — that is still a content problem. What it can do is make the existing diversity more visible and more usable for the learner.
If the learner experiences the section as a sequence, then sequence quality is part of product quality. At that point, order is no longer a technical afterthought.